Minnesang - Speak Medieval German
Project Description
Minnesang love poetry is an art form that was practiced in the Middle Ages. The Minnesang exhibit allows visitors to cite a famous medieval love poem in medieval German. Nowadays, people don't speak this language anymore. By applying the technique known as voice conversion, however, it is possible to create the illusion that a visitor speaks this language.
We envision the following scenario: Jane walks up to a large display that shows a verse of a medieval Minnesang poem in German, her native language. She reads the verse out aloud. Promptly, a video of her appears on the display: Jane sees and hears herself reciting the poem in medieval German.
Voice Conversion
Voice conversion transforms a person's utterance into the voice of another. It computes a transformation function between the voice characteristics of two speakers - the source speaker and the target speaker. This transformation function modifies the source speaker's utterance to exhibit the voice characteristics of the target speaker's voice. Parallel and non-parallel training can be used to train the transformation function.
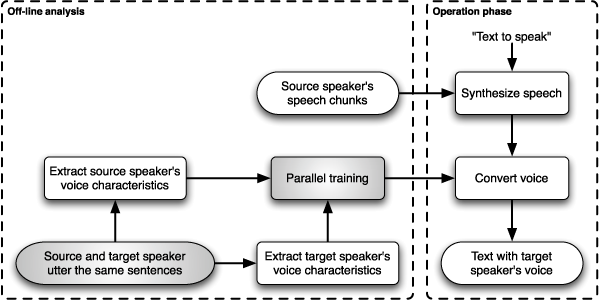
Parallel training means that both the source speaker and the target speaker utter exactly the same sentences in the same language. With a parallel speech corpus it is easy to effectively compute the transformation function. Voice conversion for Text-to-Speech Synthesis, as illustrated below, uses parallel training.
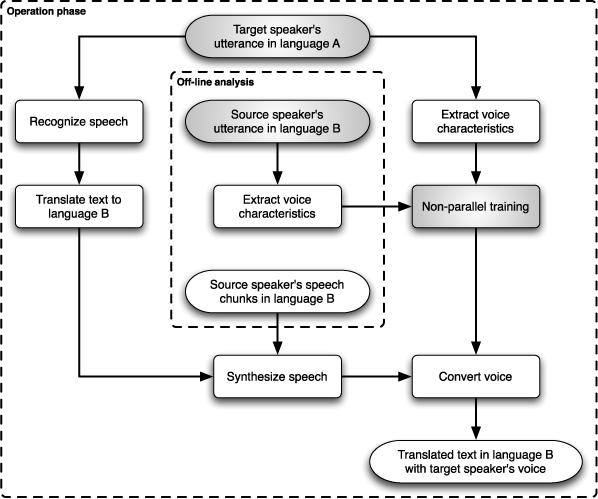
Non-parallel training means that the source speaker and the target speaker utter different sentences. It does not capture the relationship between the source voice and the target voice in as much detail as parallel training does because the speech samples do not correspond. Cross-language voice conversion is even more complicated because the source language is different from the target language - it also deals with inter-language differences besides inter-speaker differences. Voice conversion for Speech-to-Speech Translation, as illustrated below, uses non-parallel training.
The larger the training speech corpus is to compute the transformation function the better this function captures the relationship between the two speaker's voice characteristics. Today, most voice conversion algorithms rely on a large parallel speech corpus to train the conversion function. Only few approaches exist that address non-parallel training with a very limited training corpus.
Voice Conversion for the Minnesang Exhibit
Visitors from different countries may use our Minnensang exhibit. We thus need to support different target speaker languages. In the scenario described above Jane is the target speaker. She utters a short verse in German, her native language. The source speaker - a professional speaker - recorded the original poem in medieval German.
Using Jane's utterance in German and the medieval audio signal spoken by the professional speaker, we compute the transformation function with non-parallel training and then apply the conversion to the medieval audio signal. If the professional speaker also speaks German, we can use parallel training to compute the conversion function, as illustrated below.
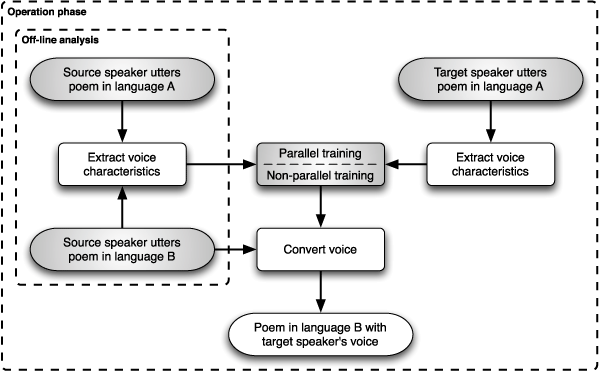
In most cases, however, the professional speaker does not speak the visitor's native language. We can use only non-parallel training to compute the conversion function. The limited vocabulary size that we can collect from the visitor poses an additional challenge to successfully compute the transformation function and to create satisfactory voice renditions in the visitor's voice.
Prototype System and Evaluation
We built a first prototype to investigate the possible interaction with our Minnesang system. Because the algorithms we had available at that time were not able to perform voice conversion in this direction, and with this small training database, with satisfactory quality, this system did not feature live voice conversion yet. Instead, it diplayed text in German or English, and contained prerecorded verses in medieval German spoken by those people who were demoing the exhibit.

This Wizard-of-Oz study worked successfully and helped us to understand how visitors reacted to the general idea of our voice conversion exhibit. We received helpful and informal feedback from the visitors watching the demonstrations. They were fascinated by the possibility to hear their own voice speaking medieval German. To improve our system, they suggested the addition of medieval music and medieval scenery to the video. Visitors would also like to take their poem recording with them as a movie.
Our next steps are to overcome the problem of limited vocabulary size to build the voice profile and to create satisfactory voice renditions even in those cases where parallel training is not possible because the visitor's native language is not part of our repertoire.
Minnesang Love Poetry
The poem that visitors will cite in the exhibit was written by Hadamar von Laber, a minstrel who lived in the vicinity of Regensburg in the 14th century. Here is a short excerpt of his famous poem Die Jagd in medieval German, German, and English.
Wie sol man rehte triuwe gerehticlîch erkennen?
Wâ ist lieb âne riuwe?
Wâ ist der stæte bunt ân allez trennen?
Wie ist gebærde, wort und werc geschicket,
swâ rehtiu liebe und stæte
mit triuwen hât den rehten bunt gestricket?
Woran erkennt man wahrhaft wahre Treue?
Wo finde ich Liebe ohne Leid?
Wo den Bund fürs Leben ohne je verlassen zu werden?
Wie verhält man sich, wie spricht, wie handelt man,
dort wo wahre, immerwährende Liebe mit Treue
den rechten Bund geschlossen hat?
How can one truly recognize a love that's true?
Where is a love that knows no grief?
Where is the steadfast bond that never breaks?
What form do gestures, words and deeds take
if ever true love and constancy with faithfulness entwine
in love's true covenant?
Visit the official Minnesang interaktiv at REX - Regensburg Experience.
Download the Minnesang Work-in-Progress published in the CHI 2006 Extended Abstracts, CHI 2006, Montréal, Canada, April 24-27.